
Capturing, processing, and transmitting video: Opportunities and challenges
StoryJuly 31, 2013

Chris Jobling
Abaco Systems

The proliferation of unmanned vehicle platforms ? in the air, on the ground, and in the water ? has provided an unparalleled opportunity to expand intelligence, surveillance, and reconnaissance operations. Choosing the optimal blend of functionality, performance, reliability, and cost is the key challenge in optimizing the use of video. Meanwhile, key considerations include sensor processing location trends, video fusion, and video compression and bandwidth, in addition to Size, Weight, and Power (SWaP).
The next wave of military evolution is being driven by the twin imperatives of the need to preserve the lives of warfighters, on the one hand, combined with the need to control operational costs on the other. These imperatives are driving substantial investment by the Air Force and Navy. Unmanned vehicles are more expendable than their manned equivalents, meaning that they can be deployed on missions that would otherwise be impossible, and they offer greater endurance.
The appearance of unmanned vehicle deployment scenarios such as cooperative missions (manned/unmanned teaming) and autonomous operations (refueling, landing/docking, sense and avoid) (Figure 1) has increased the complexity and demands of the video processing features and subsequent image data transfer.
Figure 1: The Autonomous Airborne Refueling Demonstration (AARD) program was a DARPA-funded demonstration of in-flight refueling using an autonomous aircraft. A GE COTS image processor card provided near-flawless detection, clutter rejection, and rigorous tracking of the refueling drogue in three dimensions.
(Click graphic to zoom by 1.9x)
|
|

Whatever the type of unmanned vehicle – whether land-, sea- or airborne – its mission will typically comprise three key elements: data capture, data processing, and data transmission. In addition, applications such as target tracking and data fusion have a need for time sensitivity, spatial awareness, and mutual awareness to correctly understand and utilize the data. Low-latency processing and transmission are key performance metrics, particularly where there is a human operator and key decision maker situated in a location remote from the point of data gathering. An examination of key considerations – sensor processing location trends, video fusion, and video compression and bandwidth, in addition to Size, Weight, and Power (SWaP) – lends insight.
Trends: Stay close to the sensor
As high-definition sensors become commonplace on unmanned vehicles, their increased bandwidth demands place significant processing overhead on traditional video tracking and processing systems. This trend leads to adoption of video architectures that can process the higher pixel densities, frame rates, and multiple video feeds with minimal latency. Higher definition in turn generates an exponential increase in the volume of data with associated impact on the bandwidth requirements of download links and the need to manage this through effective capture, conversion, and compression of video streams. Figure 2 shows interface bandwidth versus raw video bandwidth.
Figure 2: Interface bandwidth versus raw video bandwidth
(Click graphic to zoom by 1.9x)
|
|

One way to address this dichotomy is to do processing at the sensor as often there is no time to send data to the ground for decisions, or in doing so video fidelity might be lost (Figure 3). Processing the video locally at the sensor can be beneficial in that it is possible to extract pertinent information, such as target metrics, from the original high-fidelity imagery prior to any downscaling or compression losses, and this can be done with low latency (typically less than 1 frame) for driving subsequent decision making processes. However, this comes at the potential cost of greater power consumption in the remote vehicle, which can impact range and endurance, particularly on smaller platforms with extremely tight power constraints.
Figure 3: The trend is to process video, and to extract information of relevance, as close to the sensor as possible.
(Click graphic to zoom)
|
|

Image fusion streamlines data avalanche
The number of sensors on unmanned military vehicles is increasing rapidly, leading to a requirement for intelligent ways to present information to the operator without information overload, while reducing the power consumption, weight, and size of systems. Military and paramilitary imaging systems can include sensors sensitive to multiple wavebands including color visible, intensified visible, near infrared, thermal infrared, and terahertz imagers. To this list we can add the need to assimilate camera feeds with synthetic video such as terrain maps. Typically these systems have a single display that is only capable of showing data from one camera at a time, so the operator must choose which image to concentrate on, or must cycle through the different sensor outputs. Image fusion is a technique that allows combining complementary information from each sensor into a single, superior image that can be displayed to the operator.
Approaches to fusion include the simple additive image fusion approach, which applies a weighting to each of the input images and then linearly combines them. This has the benefits of low latency and moderate processing power, but with variable quality output, and it cannot guarantee retaining the full image contrast. In most cases, a linearly weighted fusion algorithm will produce a perfectly acceptable image that is clearly a combination of the input images and is preferable to viewing the two camera outputs side-by-side. However, in some cases the weighted average technique will result in the loss of key scene features and the fused image might not offer an enhanced view of the scene.
More advanced techniques must be employed if a higher-quality image fusion system is required. The most reliable and successful approach to fusion of two sensors uses a multiresolution technique to analyze the input images to maximize scene detail and contrast in the fused image. The added complexity of the multiresolution approach introduces an additional processing load over the linear combination technique but offers much greater scope for tailoring the algorithm to requirements and a higher-quality, more reliable fused image.
A key component of successful image fusion is input alignment to ensure that pixels in the different source images correspond to the same time and location in the real world. If this were not the case, a feature in the real world could be represented twice in the fused image, creating a confusing representation of the scene. An ideal image fusion system would contain synchronized sensors and a common optical path, but this is often not possible because of cost or other constraints.
Temporal alignment can be provided by buffering one image stream, which can compensate for unsynchronized imagers or sensors with different latencies. The process of matching one image to the other is achieved by creating a warped image. The pixel intensities of the warped image are evaluated by first calculating where in the original image the output pixel comes from and then interpolating its intensity using the values of the surrounding pixels. This can compensate for any relative rotation of the sensors, misalignment of the optical axes, or differences in the scale of the images.
Built-in warp engines can provide rotation, scale, and translation for each video source to compensate for image distortion and misalignment between the imagers, reducing the need for accurate matching of imagers with a resulting reduction in overall system cost. The systems only require a single monitor, further reducing SWaP requirements.
With the goal of fusion being to increase dynamic range and offer increased depth of field, sensor data and synthetic video (for example, terrain maps) are now being fused to provide for enhanced local situational awareness for challenging environments such as brownout.
Video compression
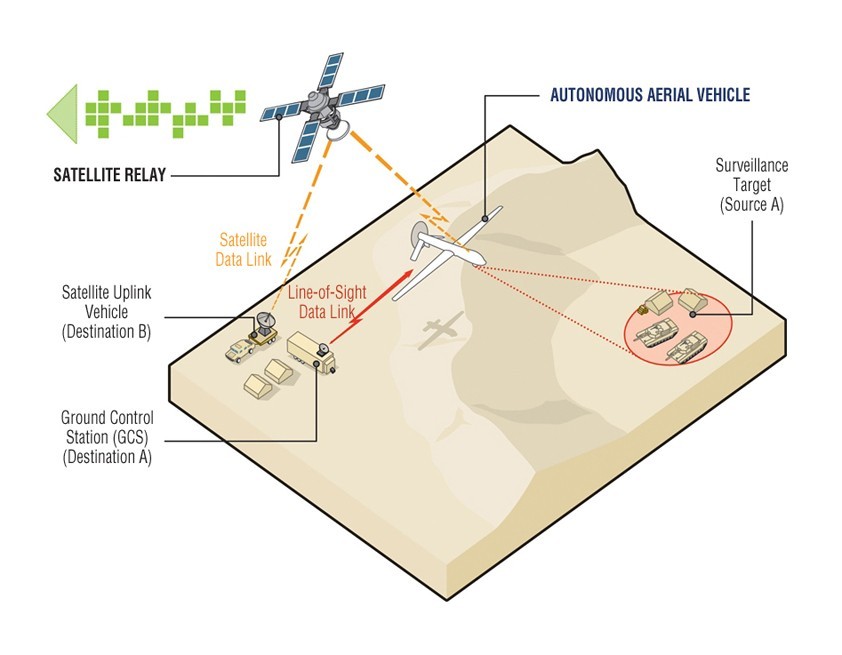
Communications bandwidth is always at a premium between an unmanned vehicle and the ground station (Figure 4). Transmitting raw captured video, for example, is at best likely to result in unacceptable delays. As such, the onboard system will typically be required to undertake significant local processing in order to identify valuable information, and discard that which has no value prior to transmission. As unmanned vehicles become increasingly autonomous – no longer guided by a ground station, and capable of adapting the mission based on real-time data – such onboard processing will assume even greater significance.
Figure 4: Communication of video imagery from the autonomous vehicle to a ground station presents significant challenges.
(Click graphic to zoom by 1.8x)
|
|
Beyond this, to reduce bandwidth consumption even further, the requirement exists to compress transmitted video, using codecs that minimize the data stream while maximizing image fidelity. The codec of choice today is H.264, also known as H.264/MPEG4, which uses around half the bit rate (or less) of previous video codecs. H.264 is popular not only because of its efficiency, but also because its applications are widespread – including in broadcast television. The implication of this is that there is a substantial infrastructure of support and expertise that can make implementing an H.264-based system both quicker and less costly for the military as well, when compared to alternatives such as JPEG2000.
Effective video compression becomes even more critical considering that new systems are adding more video sources, and increasing the image resolution from lower quality to high definition at increased frame rates. The result is up to 12x more raw data per video stream, which requires significant data compression to enable an operator to view even one video source at a control center.
The SWaP issue
Increasingly complex pixel processing chains (tracking and stabilization compression, for example) combined with a rise in the number of sensors used on each vehicle has led to a tenfold increase in the number of pixels being processed. Meeting skyrocketing video processing demands for unmanned systems while satisfying continually declining SWaP expectations is a daunting task. Combining processes such as tracking, moving target detection, image stabilization, image processing, and compression on a single board not only saves space but also results in a more tightly integrated system with lower overall power levels.
The rationalization of disparate processing tasks into a single unified processing platform is one approach that is useful in tackling this problem, and SWaP-optimized COTS-based image processing modules are already available that are designed to be placed on small platforms such as hand-launched UAVs or small unmanned ground vehicles (Figure 5).
Figure 5: GE’s ADEPT3000 system-on-module image processor is designed for highly constrained SWaP environments.
(Click graphic to zoom by 1.9x)
|
|

Ultimately, careful planning and implementation of the video architecture are crucial to any effective solution, and the use of multifunction image processors can be an effective tool in reducing the overall SWaP footprint without sacrificing performance.
Chris Jobling is Product Manager, Applied Image Processing, at GE Intelligent Platforms. He can be contacted at christopher.jobling@ge.com.
GE Intelligent Platforms www.defense.ge-ip.com




